Abstract
High Availability (HA)
As more and more critical commercial applications move on the Internet,
providing highly available services becomes increasingly important. One of
the advantages of a clustered system is that it has hardware and software
redundancy. High availability can be provided by detecting node or daemon
failures and reconfiguring the system appropriately so that the workload can
be taken over by the remaining nodes in the cluster.
In fact, high availability is a big field. An elegant highly available
system may have a reliable group communication sub-system, membership management,
quoram sub-systems, concurrent control sub-system and so on.
The CODA solution
The high availability of virtual server can be provided by using of
"coda" software. The high availability of Linux Virtual Server is illustrated
in the following figure 1.
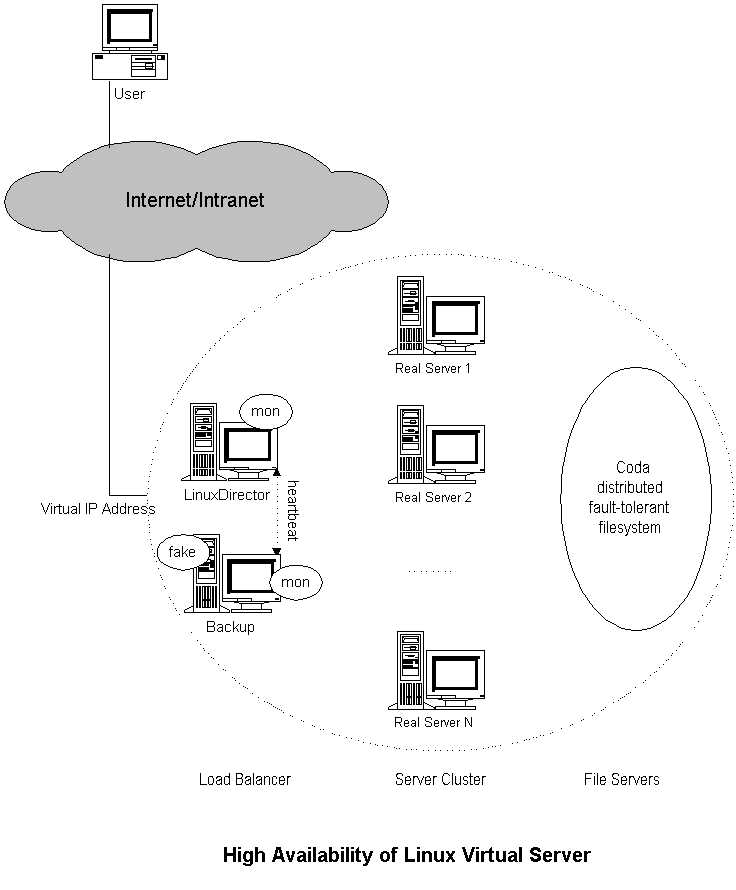
Coda is a fault-tolerant distributed file systems, a
descendant of Andrew file system. The contents of servers can be stored
in Coda, so that files can be highly available and easy to manage.
What is Coda?
Coda is an advanced networked filesystem. It has been developed at CMU
since 1987 by the systems group of M. Satyanarayanan. in the SCS department.
Why is Coda promising and potentially very important?
Coda is a distributed filesystem with its origin in AFS2. It has many features
that are very desirable for network filesystems.
Many aspects of CODA are inherited from the Andrew file system, a large
scale distributed file system that has been use in Carnegie Mellon.Like AFS,
Coda makes a distinction between servers, which are relatively few
in number, and clients , which are far more numerous. Servers are physically
secure,run trusted system software and are monitored by an operational staff.
Currently, Coda has several features not found elsewhere.
1. disconnected operation for mobile computing
2. is freely available under a liberal license
3. high performance through client side persistent caching
4. server replication
5. security model for authentication, encryption and access control
6. continued operation during partial network failures in server network
7. network bandwith adaptation
8. good scalability
9. well defined semantics of sharing, even in the presence of network failures
Current activities on Coda.
CMU is making a serious effort to improve Coda. We believe that the system
needs to be taken from its current status to a widely available system.
The research to date has produced a lot of information regarding performance
and implementation on which the design was based. We are now in a position
to further develop and adapt the system for wider use. We will emphasize:
* reliability and performance
* ports to important platforms
* documentation, mailling groups
* extensions in functionality
The current activities with Coda are mostly aimed at making this very good
filesystem widely available, and a network file system of choice.
Fig 2: Coda Logo (Illustration by Gaich Muramatsu)
Distributed file systems
A distributed file system stores files on one or more computers called servers,
and makes them accessible to other computers called clients, where they appear
as normal files. There are several advantages to using file servers: the files
are more widely available since many computers can access the servers, and
sharing the files from a single location is easier than distributing copies
of files to individual clients. Backups and safety of the information are
easier to arrange since only the servers need to be backed up. The servers
can provide large storage space, which might be costly or impractical to supply
to every client. The usefulness of a distributed file system becomes clear
when considering a group of employees sharing documents. However, more is
possible. For example, sharing application software is an equally good candidate.
In both cases system administration becomes easier.
There are many problems facing the design of a good distributed file system.
Transporting many files over the net can easily create sluggish performance
and latency, network bottlenecks and server overload can result. The security
of data is another important issue: how can we be sure that a client is really
authorized to have access to information and how can we prevent data being
sniffed off the network? Two further problems facing the design are related
to failures. Often client computers are more reliable than the network connecting
them and network failures can render a client useless. Similarly a server
failure can be very unpleasant, since it can disable all clients from accessing
crucial information. The Coda project has paid attention to many of these
issues and implemented them as a research prototype.

Fig. 3 Servers Control Security (Illustration by Gaich Muramatsu)
Coda was originally implemented on Mach 2.6 and has recently been ported
to Linux, NetBSD and FreeBSD.
Coda on a client.
If Coda is running on a client which is a Linux workstation, typing mount
will show that a file system --of type ``Coda'' -- mounted under /coda. All
the files, which any of the servers may provide to the client, are available
under this directory, and all clients see the same name space. A client connects
to ``Coda'' and not to individual servers, which come into play invisibly.
This is quite different from mounting NFS file systems which is done on a
per server, per export basis. The Andrew file system, Coda's predecessor,
pioneered the idea and stored all files under /afs. Why is a single mount
point advantageous? It means that all clients can be configured identically,
and users will always see the same file tree. For large installations this
is essential. With NFS, the client needs an up to date list of servers and
their exported directories in /etc/fstab, while in Coda a client merely needs
to know where to find the Coda root directory /coda. When new servers or shares
are added the client will discover these automatically somewhere in the /coda
tree.
To understand how Coda can operate when the network connections to the server
have been severed, let's analyze a simple file system operation. Suppose we
type: ``cat /coda/tmp/devjani'' to display the contents of a Coda file. The
cat program will make a few system calls in relation to the file. A system
call is an operation through which a program asks the kernel for service:
for example, when opening the file the kernel will want to do a lookup operation
to find the inode of the file and return a file handle associated with the
file to the program. The inode contains the information to access the data
in the file and is used by the kernel, the file handle is for the opening
program. The open call enters the virtual file system (VFS) in the kernel,
and when it is realized that the request is for a file in the /coda file system
it is handed to the Coda file system module in the kernel. Coda is a pretty
minimalistic file system module: it keeps a cache of recently answered requests
from the VFS, but otherwise passes the request on to the Coda cache manager,
called Venus. Venus will check the client disk cache for tmp/devjani, and
in case of a cache miss, it contact the servers to ask for tmp/devjani. When
the file has been located, Venus responds to the kernel, which in turn returns
the calling program from the system call. Schematically we have the following
image (figure 4).
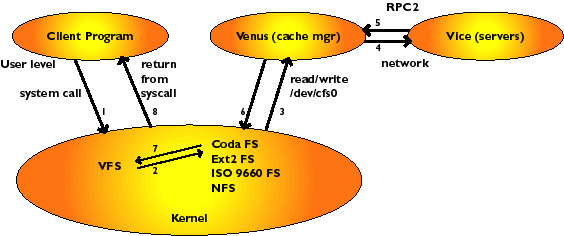
Fig 4. Client/Venus/Vice
The figure shows how a user program asks for service from the kernel through
a system call. The kernel passes it up to Venus, by allowing Venus to read
the request from the character device /dev/cfs0. Venus tries to answer the
request, by looking in it's cache, asking servers, or possibly by declaring
disconnection and servicing it in disconnected mode. Disconnected mode kicks
in when there is no network connection to any server which has the files.
Typically this happens for laptops when taken off the network, or during network
failures. If servers fail disconnected operation can also come into action.
When the kernel passes the open request to Venus for the first time, Venus
fetches the entire file from the servers, using remote procedure calls to
reach the servers. It then stores the file as a container file in the cache
area (currently/usr/coda/venus.cache/). The file is now an ordinary file on
the local disk, and read-write operations to the file do not reach Venus but
are (almost) entirely handled by the local file system (ext2 for Linux). Coda
read-write operations take place at the same speed as those to local files.
If the file is opened a second time, it will not be fetched from the servers
again, but the local copy will be available for use immediately. Directory
files (remember: a directory is just a file) as well as all the attributes
(ownership, permissions and size) are all cached by Venus, and Venus allows
operations to proceed without contacting the server if the files are present
in the cache. If the file has been modified and it is closed, then Venus
updates the servers by sending the new file. Other operations which modify
the file system, such as making directories, removing files or directories
and creating or removing (symbolic) links are propagated to the servers also.
So we see that Coda caches all the information it needs on the client, and
only informs the server of updates made to the file system. Studies have confirmed
that modifications are quite rare compared to ``read only'' access to files,
hence we have gone a long way towards eliminating client server communication.
These mechanisms to aggressively cache data were implemented in AFS and DFS,
but most other systems have more rudimentary caching. We will see later how
Coda keeps files consistent but first pursue what else one needs to support
disconnected operation.
Volumes, Servers and Server Replication
Files on Coda servers are not stored in traditional file systems. The organization
is broadly as follows. Partitions on the Coda server workstations can be made
available to the file server. These partitions will contain files which are
grouped into volumes. Each volume has a directory structure like a file system:
i.e. a root directory for the volume and a tree below it. A volume is on
the whole much smaller than a partition, but much larger than a single directory
and is a logical unit of files. For example, a user's home directory would
normally be a single Coda volume and similarly the Coda sources would reside
in a single volume. Typically a single server would have some hundreds of
volumes, perhaps with an average size approximately 10MB. A volume is a manageable
amount of file data which is a very natural unit from the perspective of
system administration and has proven to be quite flexible.
Coda holds volume and directory information, access control lists and file
attribute information in raw partitions. These are accessed through a log
based recoverable virtual memory package (RVM) for speed and consistency.
Only file data resides in the files in server partitions. RVM has built in
support for transactions - this means that in case of a server crash the system
can be restored to a consistent state without much effort.
A volume has a name and an Id, and it is possible to mount a volume anywhere
under /coda. For example, to mount the volume u.cs526 under on /coda/usr/cs526
the command cfs makemount u.cs526 /coda/usr/cs526 is issued. Coda does not
allow mount points to be existing directories, it will create a new directory
as part of the mount process. This eliminates the confusion that can arise
in mounting Unix file systems on top of existing directories. While it seems
quite similar to the Macintosh and Windows traditions of creating a ``network
drives and volumes'' the crucial difference is that the mount point is invisible
to the client: it appears as an ordinary directory under /coda. A single volume
enjoys the privilege of being the root volume, that is the volume which is
mounted on /coda at startup time.
Disconnected Operation
If all of the servers that an object resides on become inaccessible,
then the client will use the cached copy of the object (if present) as a valid
replica. When the client does this, it is operating in disconnected mode.
Disconnected mode may be the result of a network failure, or it could be
the result of removing a laptop from the network. If you make sure all of
the files you want to use are cached on your laptop, you can travel with it
and access your files as if you were still on the network.
Unfortunately, a cache miss while operating in disconnected mode is not
maskable, and you will get a connection timed out error message. Coda allows
you to mark or hoard files with caching priorities to help keep the ones
you want in the cache.
When you are in disconnected mode, you may want to checkpoint the modify
log that Coda keeps of which directories have changed. Use cfs checkpointml
to do this.
Checkpointing the modify log will ensure that changes you have made will
not be lost if the cache manager crashes severely. The checkpointed log files
are an identical copy of the in-memory logs that Coda uses when it re-integrates
with the servers.
Coda adapts easily to low bandwidth connections like (PPP or SLIP modem
links). You can use this to periodically reintegrate and cache new files
when you are on a trip.
When you reintegrate after operating in disconnected mode, keep an eye on
your codacon output or run the command:
% tail -f /usr/coda/etc/console
To support disconnected computers or to operate in the presence of network
failures, Venus will not report failure(s) to the user when an update incurs
a time-out. Instead, Venus realizes that the server(s) in question are unavailable
and that the update should be logged on the client. During disconnection,
all updates are stored in the CML, the client modification log, which is frequently
flushed to disk. The user doesn't notice anything when Coda switches to disconnected
mode. Upon re-connection to the servers, Venus will reintegrate the CML:
it asks the server to replay the file system updates on the server, thereby
bringing the server up to date. Additionally the CML is optimized - for example,
it cancels out if a file is first created and then removed.
There are two other issues of profound importance to disconnected operation.
First there is the concept of hoarding files. Since Venus cannot serve a cache
miss during a disconnection, it would be nice if it kept important files
in the cache up to date, by frequently asking the server to send the latest
updates if necessary. Such important files are in the users hoard database
(which can be automatically constructed by ``spying'' on the users file access).
Updating the hoarded files is called a hoard walk.
Server replication, like disconnected operation has two cousines who
need introduction: resolution and repair. Some servers in the VSG can become
partitioned from others through network or server failures. In this case,
the AVSG for certain objects will be strictly smaller than the VSG. Updates
cannot be propagated to all servers, but only to the members of the AVSG,
thereby introducing global (viz. server/server) conflicts.
Coda File Protection
Coda provides a close approximation to UNIX protection semantics. An
access control list (ACL) controls access to directories by granting and
restricting the rights of users or groups of users. An entry in an access
list maps a member of the protection domain into a set of rights. Userrights
are determined by the rights of all of the groups that he or she is either
a direct or indirect member. In addition to the Coda access lists, the three
owner bits of the file mode are used to indicate readability, writability,
and executability. You should use chmod(1) to set the permissions on individual
files. Coda rights are given as a combination of rlidwka where:
r - Read. Allows the user to read any file in the directory.
l - Lookup. Lookup allows the user to obtain status information about the
files in the directory. An example is to list the directory contents.
i - Insert. Allows the user to create new files or subdirectories in the
directory.
d - Delete. Allows the user to remove files or subdirectories.
w - Write. Allows the user to overwrite existing files in the directory.
k - Lock. The lock right is obsolete and only maintained for historical
reasons.
a - Administer. Allows the user to change the directory's access control
list.
Coda Terminology Conclusion References