Audio Processing
by Edward Chow
Reference: Material here
adapted from the following Related web pages and literature.
-
Davis Pan, "A Tutorial on MPEG/Audio
Compression", IEEE Multimedia, pp. 60-74, 1995.
-
Audio
Compression Overview by Dr. Ze-Nian Li at Simon Fraser University
A good technical overview
of psychoacoustics, MPEG Audio and other audio compression algorithms.
-
Tutorial
paper on MPEG/Audio Compression by Davis Pan
-
Dolby
AC-3: Multichannel Perceptual Coding at Dolby
-
FAQ
about MP3, MPEG Audio Layer 3 by Fraunhofer Institute.
-
Modern Audio Technology by Martin
Clifford, 1992, Prentice Hall,
-
Data and Computer Communications,
by William Stallings, 5th edition, 1999, Macmillan.
Element of Sound
-
Longitudinal wave: medium vibrate
in the same direction of wave advance.
-
Sound can be converted via transducer
to other form of energy for storage.
-
Inverse Square Law: the intensity
of the sound radiation decreases in proportion to the square of its distance
from the sound source.
-
Acoustic masking- one sound
can cover (mask) another making it inaudible (especially in mid- to treble
range)
-
Sound Pressure Level (SPL) is
a variation above and below normal atmospheric pressure.
-
Sound depends on the production
of changes in atmospheric pressure.
-
Audio band- 20-20kHz
0-20Hz- infrasonic
above 20kHz- ultrasonic
(supersonic)
Material here adapted from Modern
Audio Technology by Martin Clifford, 1992, Prentice Hall, and Data and
Computer Communications, by William Stallings, 4th edition, 1994, Macmillan.
Hearing-response
Characteristics

Basic
characteristics of a sound wave

Harmonics
and Tone Color
The same note play on different
musical instruments generate different tone.
The harmonics composed in
tones make them different.

Here are some math related
to the harmonics
Example
of periodical signals

Example
of phase difference

Time
domain and frequency domain

Fletcher-Munson
Curve
Human hearing does not have
flat frequency response.
More audio energy is needed
for low and high audio frequencies to produce the same sensation of loudness
as for midrange tones.
But once it is too loud,
the sensation of loudness is relatively uniform.

Noise
and frequency range of musical instruments

Sound
Measurement
The Decibel is used for comparing
strengths of a pair of acoustical or electrical powers, voltages, currents.
It is a ratio not specific absolute value.
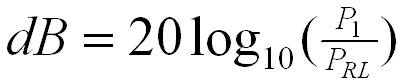
where PRL is strength of
the reference signal and P1 is the strength of signal to be
compared.

When P1=3.1PRL, dB=20*Log10(3.1PRL/PRL)=20*Log10(3.1)=20*0.49993=9.827 ~ 10. If we use 3.162 instead 3.1, it will closer to 10.

Measurement
of Sound Pressure
bar (barometric)- an CGS
unit of atmospheric pressure
= 106 dyn/cm2.
= 14.7 lb/in2 at
sea level
The sound pressure received
by microphone is much smaller and is measured in terms of a millionth of
an atmosphere or in microbars.
a threshold of hearing begin
~ 0.0002 mbar.
Dyn is defined as the force
that will produce a velocity of 1 cm/sec when acting on a mass of


Microphone
Measurements

Sound
range in dBs

Digital
vs. Analog
Reality: signal got distorted
over distance because
-
impedance (within transmission
medium)
-
interference (outside force,
e.g. cloud, lightening)

Data
Encoding and Modulation

Modulation
of analog signals for digital data
Pulse
Code Modulation (PCM)


Quantization
error can be reduced by having higher sampling rate (sample more frequently)
and more quantization level (more bits for each sample).
Example:
With
Stereo, 16 bits/sample, 44kHz sampling rate, PCM encoding, how many bits
of data will be generated by a three minute sound recording?
Ans: 3min*60sec/min*44000samples/sec*16bits/sample*2(channel)/8bits/byte=31.68MB/s
Masking
-
A phenomenon of the human hearing
system. Normal human ears are sensitive to a wide range of frequencies.
However, when a lot of signal energy is present at one frequency, the ear
cannot hear lower energy at nearby frequencies.
-
We say that the louder frequency
masks the softer frequencies. The louder frequency is called the masker. Here is the digram the depict what masking phenomenon:
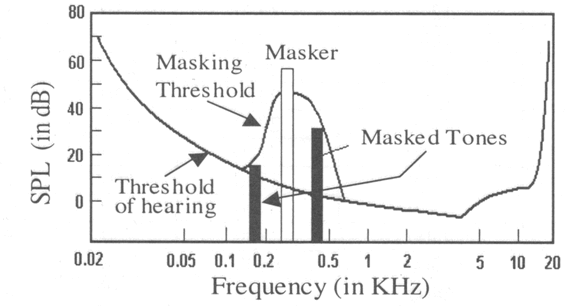
Figure 2.5. Audio masking threshold. (from Mirinal Mandal's "Multimedia Signals and Systems") , The threshold of hearing determines the weakest sound audible by the human ear in the 20-20KHz range. A masker tone (at 300 Hz) raises this threshold in the neighboring frequency range. It is observed that two tones at 180 and 450 Hz are masked by the masker, i.e., these tones will not be audible. SPL: sound pressure level.
Sub
Band Coding (SBC)
-
The basic idea of SBC is to
save signal bandwidth by throwing away information about frequencies which
are masked.
-
The result won't be the same
as the original signal, but if the computation is done right, human ears
can't hear the difference.
-
Divide signal into bands and
perform masking computation and throw away weak signals in each band.
MP3:
MPEG Audio Layer 3
-
It is a perceptual audio coding
scheme, exploiting the masking property of the human ear, and trying to
maintain the original sound quality as far as possible.
-
MPEG Audio specifies a family
of three audio coding schemes, simply called Layer-1, Layer-2, and
Layer-3. From Layer-1 to Layer-3, encoder complexity and performance (sound
quality per bitrate) are increasing.
-
In MPEG 1 Audio standard,
-
all three layers may use 32,
44.1 or 48 kHz sampling frequency.
-
All Layers are allowed to work
with similar bitrates:
Layer-1: from 32 kbps to 448 kbps
Layer-2: from 32 kbps to 384 kbps
Layer-3: from 32 kbps to 320 kbps
-
In MPEG-1: max. 1.5 Mbits/sec
for audio and video, About 1.2 Mbits/sec for video, 0.3 Mbits/sec for audio
-
In MPEG 2 Audio standard, there
two new extensions:
-
low sample
rate extension: extend sampling rates to 8, 16, 22.05 or 24 kHz.
-
multichannel
extension: address surround sound applications, with up to 5 main
audio channels (left, center, right, left surround, right surround) and
optionally 1 extra "low frequency enhancement (LFE)" channel for subwoofer
signals;
-
multilingual
extension: allow the inclusion of up to 7 more audio channels.
-
Compression ratios: MP3 achieve
1:10-1:12 compression ratio, at about 64 kbit/s per audio channel, while
maintaining the original CD sound quality .
-
MPEG Audio Algorithm
Steps in algorithm:
-
Use convolution filters to divide
the audio signal (e.g., 48 kHz sound) into frequency subbands that approximate
the 32 critical bands --> sub-band filtering.
-
Determine amount of masking
for each band caused by nearby band using the results shown above (this
is called the psychoacoustic model).
-
If the power in a band is below
the masking threshold, don't encode it.
-
Otherwise, determine number
of bits needed to represent the coefficient such that noise introduced
by quantization is below the masking effect (Recall that 1 bit of quantization
introduces about 6 dB of noise).
-
Format bitstream

Example:
-
After analysis, the first levels
of 16 of the 32 bands are these:
----------------------------------------------------------------------
Band 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
Level (db) 0 8 12 10 6 2 10 60 35 20 15 2 3 5 3 1
----------------------------------------------------------------------
If the level of the 8th band
is 60dB,
it gives a masking of 12
dB in the 7th band, 15dB in the 9th.
Level in 7th band is 10 dB
( < 12 dB ), so ignore it.
Level in 9th band is 35 dB
( > 15 dB ), so send it.
--> Can encode with up to
2 bits (= 12 dB) of quantization error.
MPEG Layers
Audio
Recording and Editing Tool: Adobe Audition
-
Audition is a audio editing software that
records, playbacks, and editing sound files, and provides utilities for coverting the sournd files in different format.
-
For the recording exercise,
you can use PCs in El Pomar media library, and bring your own headset with
a microphone. The red/microphone connector go to the socket with the red microphone symobl in the sound card or that under the front panel cover. The black/headset speaker connector go
to the socket with the headset symobl in the sound card or that under the front panel cover.
- Due to health reason, the school no long lends out the headset. I have a light microphone you can check out from me.
-
Select Start | Program | Audition 1.5 or click on the Audition icon,
 on the desktop, and the following main window appear.
on the desktop, and the following main window appear.
-
Select File | "new" menuitem,
"New Waveform" dialog window appear.
-
Specify the sampling frequency,
bits per sample, and mono/stereo.

For human speech we can
get by with 11kHz, 8bit, and mono setting.
For singing, we can increase
from 11 kHz to 22 kHz.
For music recording, use
44kHz and 16 bit.
Hit OK after choosing the
sampling parameters.
-
Press "Record" button on the
lower left corner of the screen to start recording.
- Hit "Stop" button when you
are done.
The recorded wave form will
be displayed on the main window.
-
Most of the time, the signal
will be pretty weak.
- Select Transform | Amplify
| Normalized menuitem to enhance the signal to a "normal" level.
-
Editng the sound file by
selecting the area (point and drag) of the wave form and hit "delete" button.
-
Select File | save as menuitem.
Choose filename and audio file type, typically .wav (Microsoft) format or .mp3 format.
-
.ra provides quite impressive
compression ratio.
Audition can save sound as .wav or .mp3 but not .ra file. Real Audio encoding considers the speed of the transmission media and provides even higher compression ratio. See the example below. It is more than 5:1 ratio.
To convert among wave, mp3, to rm audio file, you can use file converter such as mp3 rm converter, http://www.mp3towav.org/MP3-RM-Converter/
To play back real audio file, download the basic real player 10 from http://www.real.com/.
Here are three sample
audio files generated by CoolEdit an earlier version of Audition:
Vincent
singing 176KB, au format and
Vincent
singing, 178KB, wav format,
Vincent singing, 113KB, mp3 format and
Vincent
singing, 33KB, realaudio format,
WavePad:
- NCH Swift Sound provides a freeware WavePad audio editing tool. It has the same basic editing capability. Besides saving pcm .wave and MP3 files, it can also generate RSS Podcast audio format (actually it is .rss with .mp3).
- Example of .RSS file generated:
<?xml version="1.0" ?>
<rss version="2.0">
<channel>
<title>MikeInStadium</title>
<description>MikeInStadium</description>
<link>http://cs.uccs.edu/~cs525/audio/wavepad/</link>
<item>
<title>MikeInStadium</title>
<description>MikeInStadium</description>
<enclosure url="http://cs.uccs.edu/~cs525/audio/wavepad/MikeInStadium.mp3" length="94877" type="audio/mpeg" />
</item>
</channel>
</rss>
- Text-To-Speech: WavePad also contains text speech option (need to download speechapi.exe and mstts.exe from http://www.nch.com.au/speech/ or http://www.microsoft.com/msagent/downloads.htm
- Here is the sound file that include first my voice recording, following by a text-to-speech synthesis results for "This is a CS525 test." with "Mike in Stadium" voice characteristic setting.
- Potential research project: Study Agent SDK and explore the use of a window machine as a server, that given an text input (stream), produce a mp3 voice stream.
Exercises:
-
With mono, 16 bits, 22kHz, PCM
encoding, how many bytes of data will be generated by a three minute sound
recording?
-
Use Audition to record a less
than 5 second voice with mono, 16 bit, 22kHz, encoding. Edit out the unnecessary
silence portion of the sound track and apply the normalized special effect.
Save it in .wav file and .mp3 formats. sFtp the two audio files to your cs525 home page directory
and create a hyperlink in your class personal web page.
-
In EN233/EN138/A210 lab, we have MATLAB software package which allows to specify waveform and generate the correponding audio wave file for testing. We can use it to verify the audio masking concept used in MP3. The following MATLAB code from Mirinal Mandal's "Multimedia Signals and Systems" textbook example 2.1 will generate three wave files that demo strate the audio masking concept.
fs=44100; % sampling frequency
nb=16; % 16-bit/sample
sig1=0.5*sin(2*pi*(2000/44100)*[1:1*44100]); % 2000 Hz, 1 sec audio
sig2=0.5*sin(2*pi*(2150/44100)*[1:1*44100]); % 2150 Hz, 1 sec audio
sig3=[sig1 sig1+sig2]; % 2000 Hz and 2150 Hz tones are equally strong
sig4=[sig1 sig1+0.1*sig2]; % 2000 Hz is 20dB stronger than 2150 Hz
sig5=[sig1 sig1+0.01*sig2]; % 2000 Hz is 40dB stronger than 2150 Hz
wavwrite(sig1, fs, nb, 'C:\work\cs525\S2010\chow\sig1.wav');
wavwrite(sig2, fs, nb, 'C:\work\cs525\S2010\chow\sig2.wav');
wavwrite(sig3, fs, nb, 'C:\work\cs525\S2010\chow\test1.wav');
wavwrite(sig4, fs, nb, 'C:\work\cs525\S2010\chow\test2.wav');
wavwrite(sig5, fs, nb, 'C:\work\cs525\S2010\chow\test3.wav');
Follow the following step to generate the wave files.
- Login to A210 PC with your csnet account. Double click on the MATLAB R2009a icon, similar to
 on the desktop to start the application.
on the desktop to start the application.
- Alternatively, you can also use remote desktop connection to login to rats or lats.eas.uccs.edu from home with your ufp account. Make sure you select "ufp" domain on the 3rd "log on to " selection.
- They are win2003 servre. For MathLab, select the MATLAB R2009b icon on the desktop, or start | All Programs | MATLAB | R2007B | MATLAB R2009b.
- In the "My Computer" verify that your ufp directory is mapped as Z: drive.
- If it is, create a cs525 directory there and copy the above Mathlab code into the lower right command window. It will generate the thress test wave files.
- If you can not find yoru ufp directory and you would like to use the c:\temp directory for saving the , you need to replace the "Z:\cs525\" path in the last three command of the above mathlab code with "C:\temp" and then copy it into the command window.
- Play the three wave files. Verify that in test2.wav you barely detect the 2150 Hz sound which is 20dB or 0.1 weaker, and in test3.wav, you cannot detect the 2150 Hz sound which is 40dB or 0.01 weaker.
- Note that the masking threshold is subjective, varying from person to person. You may want to experiment with the dB ratio and see how sensitive your ear is.

